This is the first chapter of the tutorial series: Implement a RecSys.
- Chapter 1: Introduction and Project Overview
- Chapter 2: Understanding the Data and Feature Engineering
- Chapter 3: Negative Sampling
- Chapter 4: Offline Evaluation, MLflow Experiment Tracking, and Baseline Implementation
- Chapter 5: Design Session-based Recommendation System
- Chapter 6: Preparing for Serving
- Chapter 7: Building the API Layer
Introduction
Imagine you’re browsing an e-commerce site and notice something very interesting: the recommendations update almost instantly as you click through products. You view a pair of headphones, and suddenly phone cases, audio cables, and portable chargers appear. You check out a laptop, and the “you might also like” section refreshes with wireless mice, laptop bags, and USB hubs. You think to yourself—How do they capture your evolving intent so quickly? How do they serve personalized suggestions fast enough to feel real-time? How do they handle the complexity of understanding your browsing patterns on the fly?
If you’ve ever have those questions, this tutorial series is for you.
Over the next 7 chapters, I’ll walk you through building an end-to-end recommendation system that reacts in real-time based on user behavior sequences. We’ll go from raw data to a complete recommender system that personalizes recommendations as users interact with your platform. The final product looks like this:
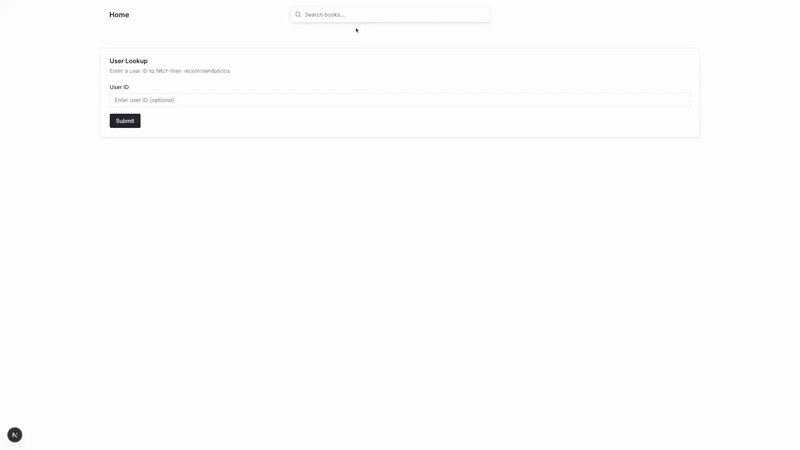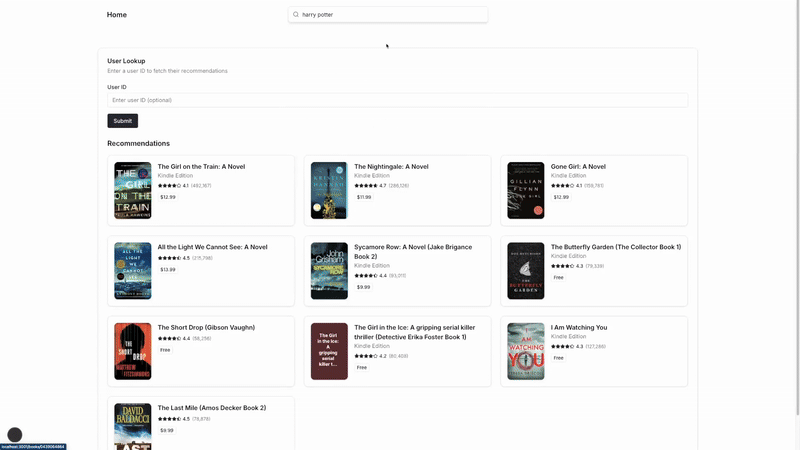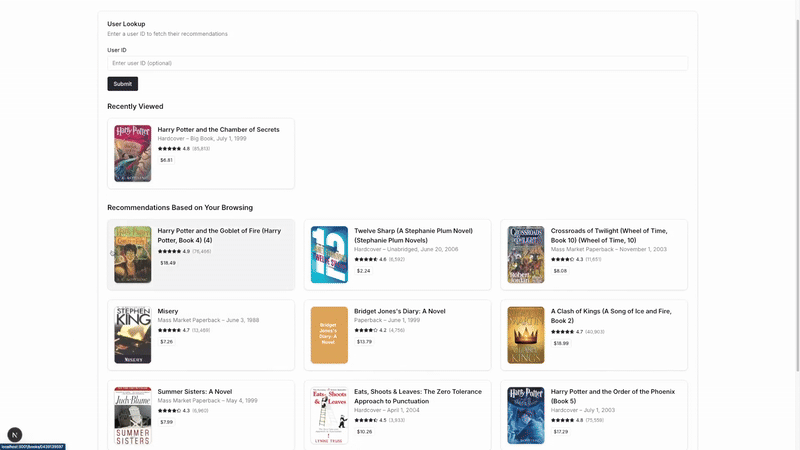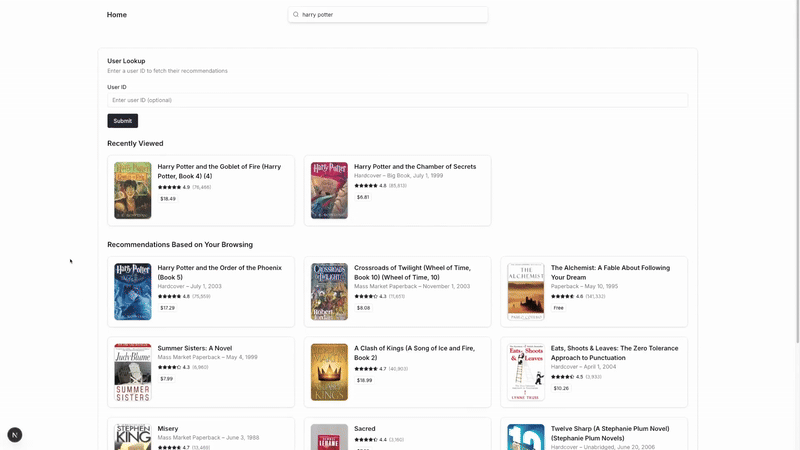
If you’re familiar with RecSys and just want to see the code, here it is: https://github.com/dvquy13/recsys-seq-model.
A quick recap for those who aren’t well aware of what a recommender system is: Recommender systems are specialized tools designed to suggest items—whether products, content, or services—to users based on what we know about their preferences and behaviors. At their core, they comprise a set of technologies, algorithms, and processes that analyze user interaction signals (clicks, views, purchases, ratings, etc.) to predict what individual users might find relevant or engaging.

From the user’s perspective, these systems help uncover content or products they might never have discovered on their own and save time by surfacing the most relevant options up front.
From a business standpoint, the primary goals of a recommender system are to create a sense of “we understand you” for each user and to drive revenue through personalized cross-selling opportunities. By tailoring recommendations to each user, companies can boost engagement and average order value.
In practice, recommender systems power some of the world’s largest digital platforms. For example, Amazon’s “Frequently Bought Together” suggestions guide shoppers toward complementary products, Facebook uses recommendation algorithms to prioritize posts and ads in users’ feeds, and Netflix’s home screen is largely driven by personalized movie and show recommendations.
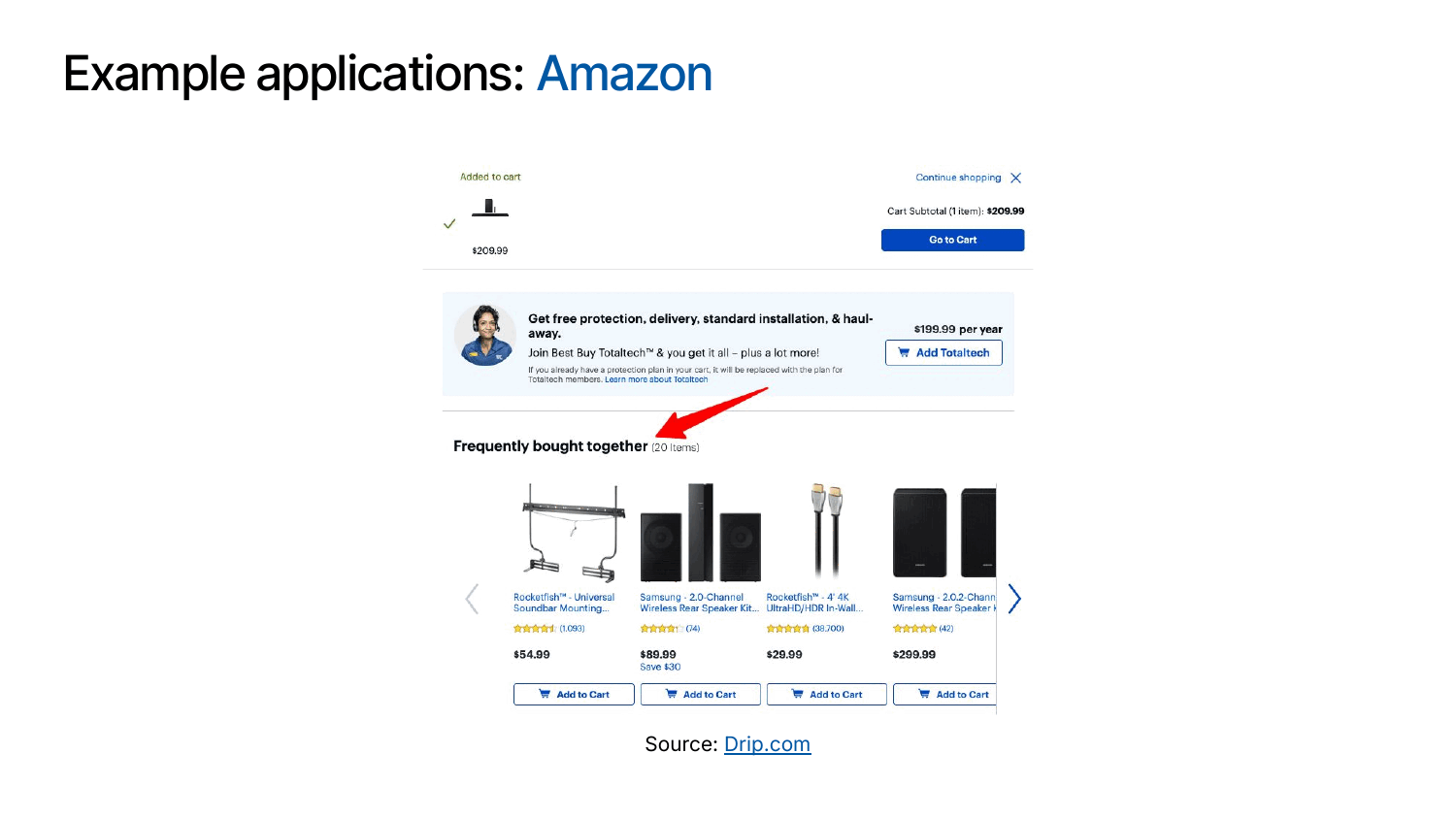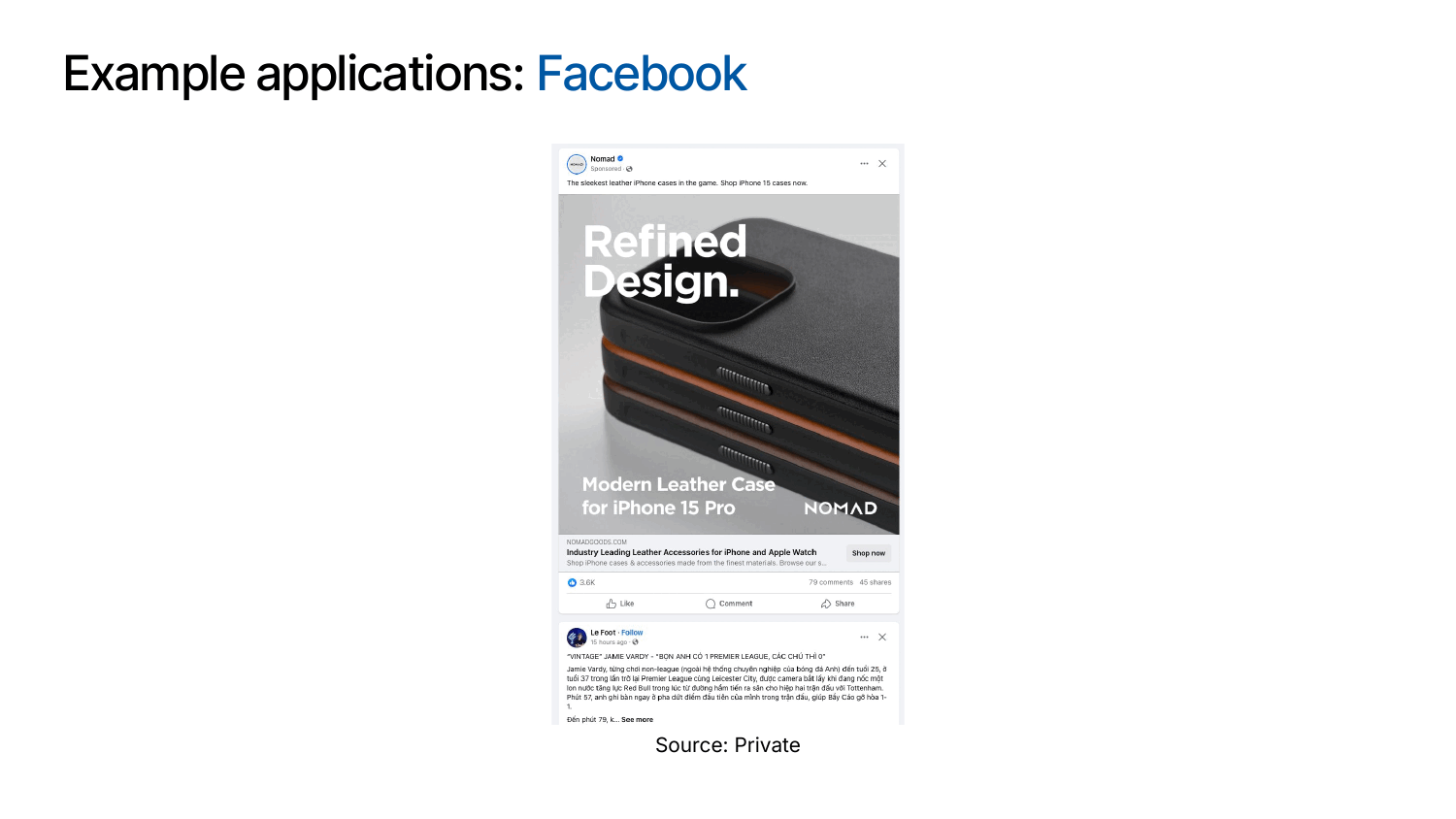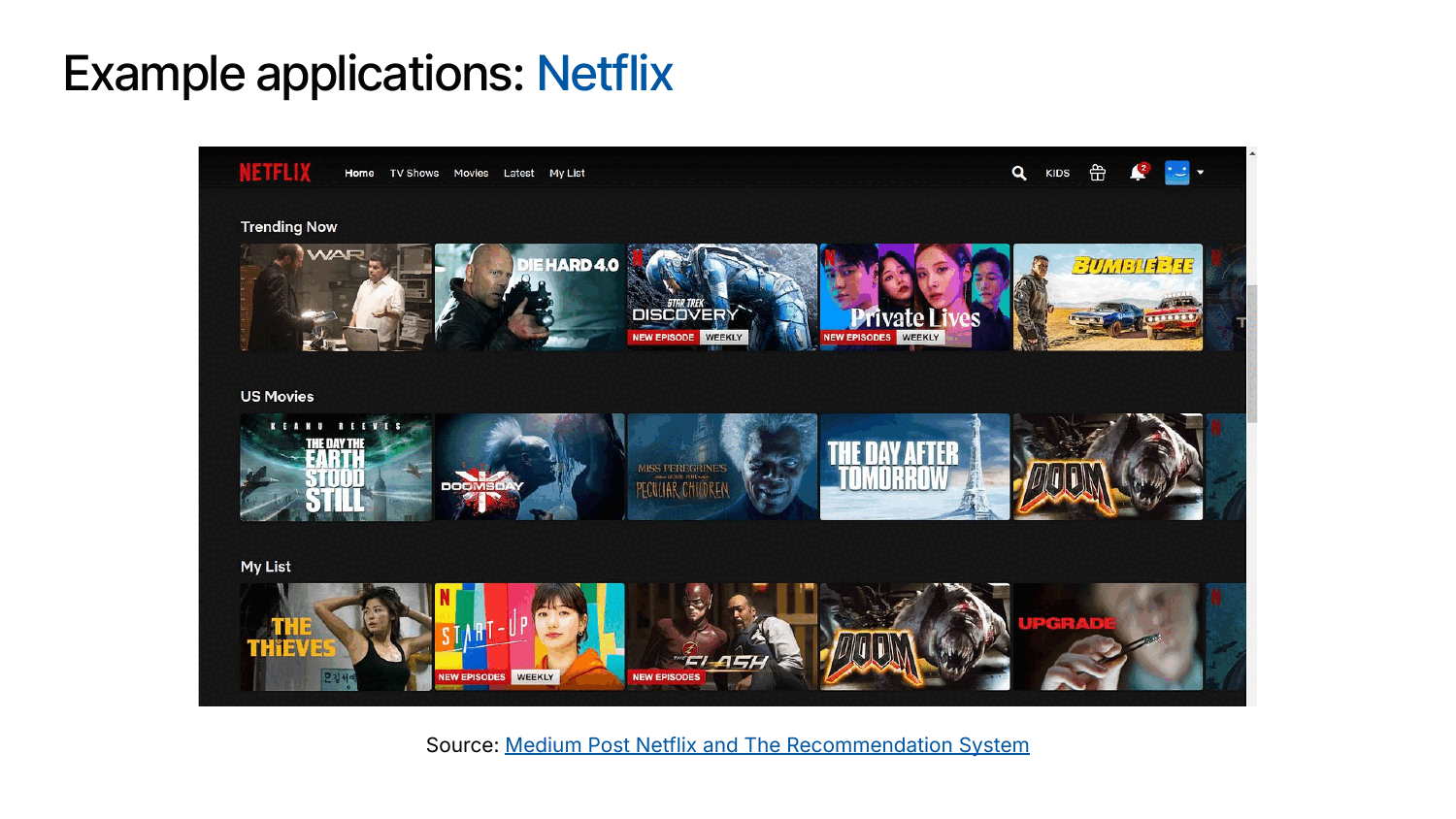
The impact of these systems is profound: According to this report from McKinsey, roughly 75 percent of Netflix viewing hours come from recommended titles, 35 percent of Amazon’s purchases are influenced by its recommendations, and Netflix alone saves around $1 billion per year through improved user retention and engagement. These metrics underscore why recommender systems have become a critical component of modern digital businesses.
What You’ll Build
By the end of this series, you’ll have constructed an end-to-end recommendation system while knowing how to:
- Design and Train Session-based RecSys models to personalize recommendations in real-time based on users’ recent interaction sequences
- Handle complex data engineering challenges including sampling techniques that avoid sparsity cascade, sequence generation from timestamps, and popularity-based negative sampling
- Track experiments with MLflow for reproducible ML workflows, automated model versioning, and systematic performance comparison
- Implement a PyTorch sequential retrieval architecture optimized for serving millions of items with millisecond response times
- Deploy model servers using BentoML with seamless MLflow integration
- Build recommendation serving pipelines through a FastAPI orchestrator that coordinates vector similarity search, user context retrieval, and fallback strategiesz
- Mimic production infrastructure setup with Docker Compose orchestrating MLflow (model registry), Qdrant (vector database), and Redis (key-value store)
Target Audience
This tutorial series is designed for:
- Data Scientists looking beyond training models and into ML services
- ML Engineers building scalable recommendation systems
- Backend Developers interested in ML/RecSys architecture
- Anyone curious about a modern and real-time end-to-end RecSys project
In most of the discussions, I assume readers have basic understanding of Machine Learning and Python to follow along.
Session-Based vs Traditional Recommendations
Traditional recommendation systems often rely on collaborative filtering, which uses historical user-item interaction signals to find similar users or items. While effective, these approaches have limitations:
- Static representations: User preferences are treated as fixed
- Cold start problems: Difficulty with new users or items
- Limited temporal understanding: Doesn’t capture evolving user interests within a session
Session-based recommendation systems take a fundamentally different approach by focusing on user behavior patterns within individual sessions or short time windows. Instead of building static user profiles from historical data, these systems analyze the sequence of actions a user takes during their current browsing session—the order they click through products, the time they spend on each item, and how their interests evolve in real-time.
Consider a typical e-commerce browsing session that illustrates why this sequential understanding matters:
- User searches for “wireless headphones”
- Views a Sony model
- Checks reviews for Audio-Technica alternatives
- Compares prices across brands
Each step provides context for the next recommendation. Traditional systems might miss this sequential pattern and treat each interaction independently, while session-based models capture the evolving intent throughout the entire journey—understanding that the user is comparison shopping for headphones within a specific price range.
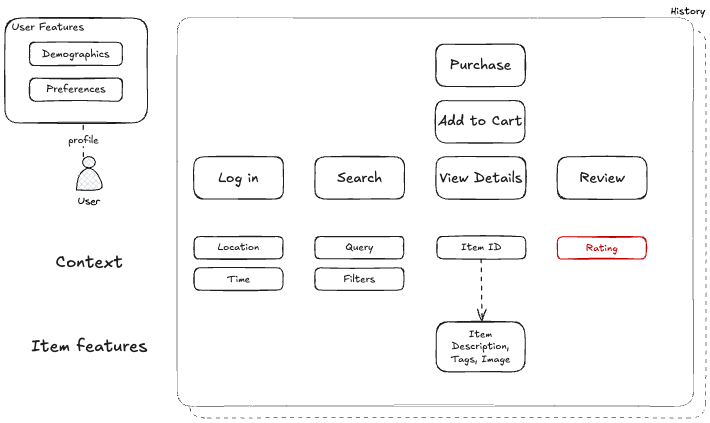
In essence, this approach addresses the limitations of traditional methods by:
- Modeling sequences: Understanding the order and timing of user interactions
- Capturing short-term intent: Focusing on recent behaviors within a session
- Handling anonymity: Working even without persistent user identifiers
- Real-time adaptation: Continuously updating recommendations as users interact
Now that we understand why session-based recommendations make sense, it might be tempting to jump straight into building one. But I would advise you to hold on, cause there’s still one big question we need to address: How do you ensure your model gets access to the data it needs? When talking about serving this kind of real-time model in production, even the most powerful one is useless if it can’t receive timely user interaction signals.
A Simplified Payload Approach
Large-scale real-time recommendation engines are typically built on top of streaming architectures with event pipelines (Kafka, Kinesis, etc.) that process user interactions. The streaming system is normally managed in a centralized manner by a platform team with the aim to provide real-time data processing capabilities to multiple downstream usages. This approach also ensures scalability and reliability.
However, for the purpose of this tutorial, we can relax the requirements of serving multiple use cases. This leaves us with more room to think about how we can approach getting real-time user signals. Why can’t we just ask our app client to store and directly provide us the recent user interactions as context whenever it requests our recommendation service?
If the answer is yes, then I have a name for our approach: The Simplied Payload.
Basically we would attach the real-time events along with the requests coming to our RecSys APIs (in the payload—hence its name). In practice, this implementation can be done by frontend engineers capturing user interactions locally (clicks, views, etc.).
While this approach looks like a hacky-workaround ways, I have seen teams using this in production for early-stage real-time ML RecSys. When really thinking about it, the idea has some merits in and of itself. They include (1) minimal signal delay, (2) users not needing to refresh to get updated recommendations and (3) easier to implement and debug. (4) User privacy is another reason worth considering.
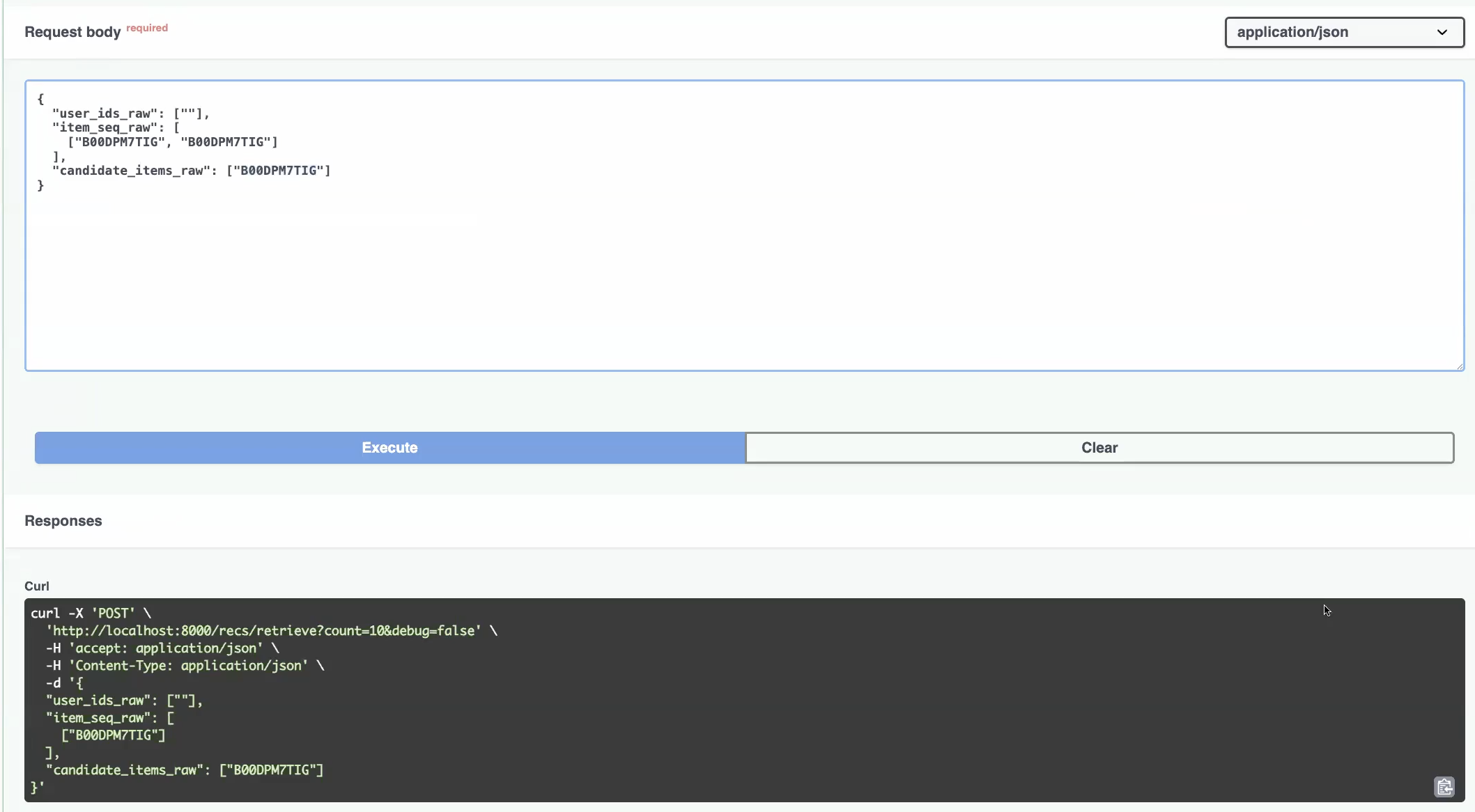
In the below screenshot you can see that in the POST request payload sending to a recommendation endpoint, we include the recent user interacted item IDs in item_seq_raw in the payload.
Our Technology Stack
Below is a list of the technology frameworks we use in this project. There is no need to understand all of them in detail, so do not worry too much if you are not familiar. However, I do encourage you to at least learn the basics of each of them. Wherever possible I would also explain the rationale and what roles they play in the system that we build together.
| Component | Technology | Purpose |
|---|---|---|
| ML Framework | PyTorch | Deep learning model training |
| API Server | FastAPI | High-performance API endpoints |
| Model Server | BentoML | Model server |
| Experiment Tracking | MLflow | Model versioning and experiments |
| Vector Database | Qdrant | Similarity search and retrieval |
| Caching | Redis | Real-time data storage |
| Package Management | uv | Fast Python dependency management |
| Containerization | Docker | Consistent deployment environments |
Project Structure Overview
The codebase can be found here. Below is a quick glance into its structure.
recsys-seq-model/
├── notebooks/
│ ├── 000-prep-data.ipynb
│ ├── 001-features.ipynb
│ ├── 002-negative-sample.ipynb
│ ├── 010-baseline-popular.ipynb
│ ├── 011-sequence-modeling.ipynb
│ ├── 020-ann-index.ipynb
│ └── 021-store-user-item-sequence.ipynb # Sequence storage
├── src/ # Core implementation modules
│ ├── cfg.py # Configuration management
│ ├── dataset.py # Data loading utilities
│ ├── id_mapper.py # ID mapping functionality
│ ├── negative_sampling.py # Sampling strategies
│ ├── sequence/ # Sequence model implementations
│ ├── eval/ # Evaluation frameworks
│ └── vectorstore.py # Qdrant integration
├── api/ # FastAPI Orchestrator service
│ ├── app.py # Main application
│ ├── services.py # Business logic
│ └── models.py # Request/response schemas
├── model_server/ # BentoML model server
├── data/ # Dataset storage
├── compose.yml # ML support toolings
└── compose.api.yml # Build API servicesNotice the numbered notebook sequence (000, 001, 002, etc.). This design ensures you build knowledge progressively:
- 000-series: Data preparation and exploration
- 010-series: Model training and evaluation
- 020-series: Post-training preparation for serving
Each notebook represents a complete milestone, allowing you to pause and resume at any point.
A note on the commonly used commands
You may found the below commands useful, as I have myself running them regularly when developing the projects. I have put them in the Makefile as they are my shortcuts:
# Install Python dependencies
uv sync --all-groups
# Start Jupyter Lab
make lab
# Start supporting tools like MLflow and check their logs
make ml-platform-up && make ml-platform-logs
# API Services
make api-up
make api-test
# Start the Demo
make ui-up
# Shut down all services
make downRecap
To get a hand on the system that we will build together, you can clone the repo and follow the instructions in the README to get the project running. If you’re familiar with the technical details, mainly exploring the code and occasionally come back to the blog series for rationale/design decisions may be a great way to get the most from the tutorial.
After following the README (hopefully no issues), you should have:
- A clear picture of what session-based recommendations are and why they’re useful
- Your development environment ready to go with all services running
- Familiarity with the project structure so you can navigate the codebase
- The foundation knowledge to tackle the upcoming chapters
What’s Next
For those who want a linear progression, let’s get started! Here’s a preview of the roadmap ahead of us:
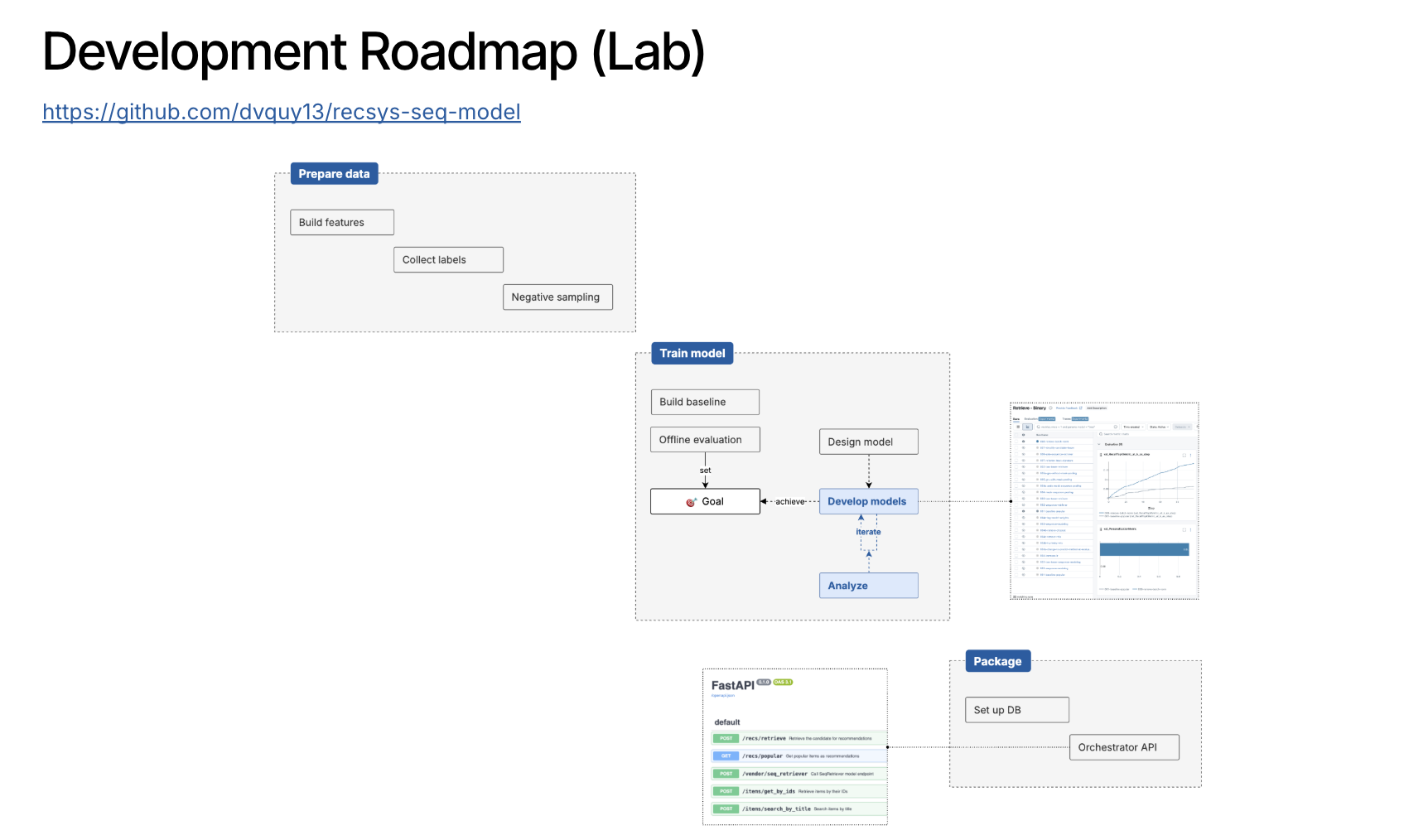
In Chapter 2, we’ll get our hands dirty while setting up the input data in a format that’s designed for sequence modeling.
Continue to the next chapter.
If you find this tutorial helpful, please cite this writeup as:
Quy, Dinh. (May 2025). Implement a RecSys, Chapter 1:
Introduction and Project Overview. dvquys.com. https://dvquys.com/projects/implement-recsys/c1/.