Imagine a company named Rainbow imports boxes of flowers and need to classify them into species. For six months, they have some staff label the boxes manually. Now, they hire you to build a Machine Learning model to do the task.

With a small amount of labelled data as input and tons of experience working on Kaggle projects, you quickly develop a 95% accuracy using simple RandomForestClassifier from the popular scikit-learn library. Nice. Stakeholders approve and ask you when you could deploy that model to production.
Hmm, deploy a model from my laptop? …
In case you wonder, I hope this tutorial will help you understand one among some common and most simple approaches. The diagram below depicts how we will use Google Cloud Platform to do the job in a batch-processing manner.
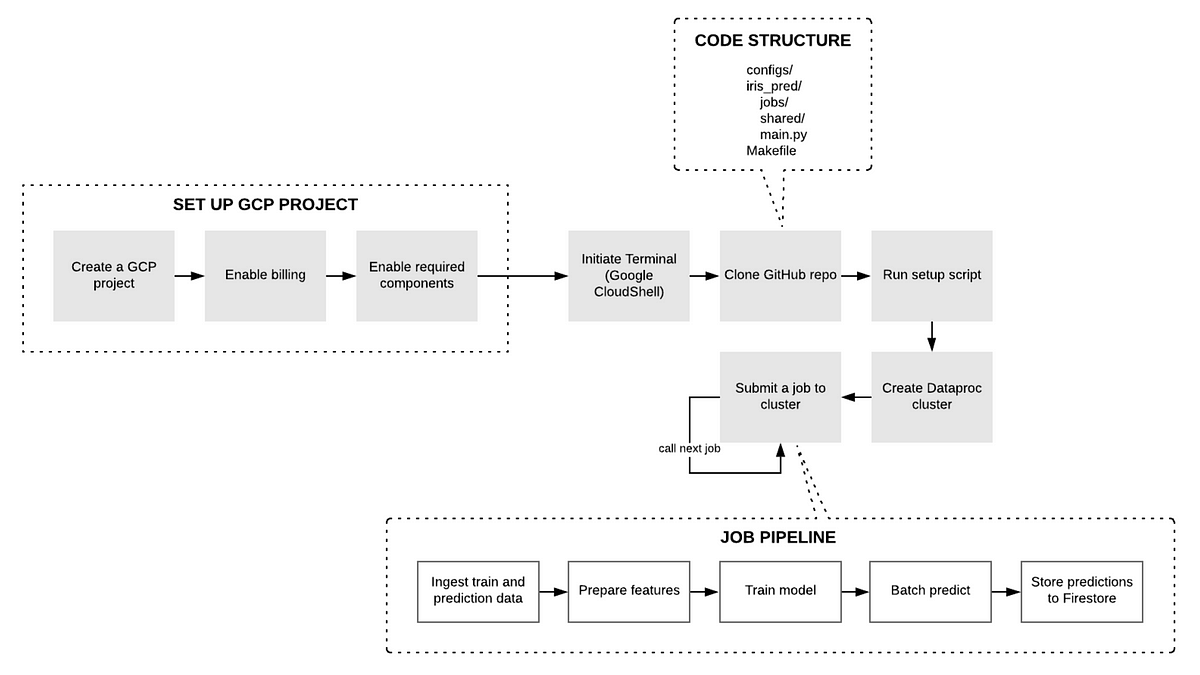
I choose the Iris data set as our input to help you see how our approach works with small-sized problems. All the codes are in this repo.
Introduction
Like many other self-taught data people, I am familiar with manipulating data and develop a model on my laptop.
However, when you’re solving real-world problems, your duty does not stop after you deliver a presentation. You will have to think about how to bring that solution to the production environment.
Over the last few months, I have tried to deploy multiple computing pipelines. They are different in their scopes and complexity, ranging from processing a dozen of MB to 400 GB data per run. In this article, I want to summarize and share what I learned.
The targeted audience
This post is for data analysts/scientists who want to deploy their local solution, especially those without a software engineering background.
You will need Cloud Dataproc to proceed. This product allows you to spin up a cluster of machines to run your computing job in a distributed manner. Please refer to this documentation if you don’t know what Dataproc is.
Agenda
- Discuss the approach
- Step-by-step instructions to create the infrastructure and run the pipeline
- Explain codebase
- Introduce other extended components, including Big Data processing with Apache Spark, scheduler with Airflow, local development environment, unit testing
- Summary
Approaches
About writing codes
Instead of writing a long script to do everything, we break a pipeline into tasks and checkpoint interim data to disk. For example, after doing preprocess on train and test data, we dump both the data outputs and the transformer to Google Cloud Storage. We then load those objects as inputs for the next step.
This strategy has several purposes. First, for a long-running task, if a job fails at one of the last steps, we can re-run the pipeline from the nearest checkpoint rather than wasting time and resources restarting the whole pipeline. Second, it allows us to (1) debug more easily, (2) get alert when things break and (3) monitor interim outputs. Lastly, decoupled components can be understood more clearly, and easier to be replaced or extended later.
About computing resources
Normally for a small input size, we are fine with setting up a single virtual machine on the cloud. However, in some companies with mature cloud practice, the overhead of managing that VM is a type of cost that is difficult to justify. Especially when we have better options. For instance, Cloud Dataproc provides us with virtual machines that only live for the duration of one run, thereby free us from managing the machines. In this post, we explore Dataproc as our main engine for all the computing process.
Step-by-step instructions
Create a GCP project and enable necessary components
- 👉 Create a free GCP account with $300 credit by going to console.cloud.google.com. Beware that by following this tutorial, you might incur a cost of about $0.2–$0.5.
- 👉 Click Billing at the left sidebar and initiate a billing account to be able to use the components used in this tutorial
👉 Select Library, then search and enable the following API: Cloud Dataproc, Cloud Storage and Cloud Firestore.
👉 Navigate to the Firestore either by scrolling the sidebar to the left or search from the top menu bar. When you arrive at the below screen, choose SELECT NATIVE MODE, then choose
us-east1as the location.
Environment setup
Step 1: Launch terminal window
- 👉 At the home page of your GCP project, select the command button to the right of your menubar. The CloudShell window then appears as you can see below:
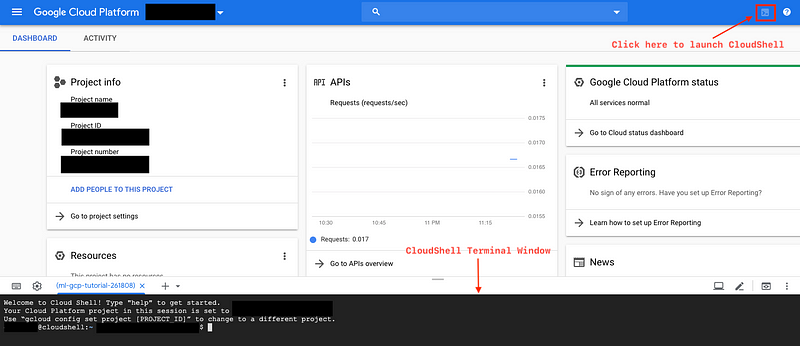
- 👉 Launch Cloud Shell Editor:
It’s recommended to use Cloud Shell to follow this tutorial. However, if you’re using Linux and want to use terminal on your local machine, make sure you first install the Google Cloud SDK and firebase CLI.
Step 2: Clone Github repo
- 👉 In the Terminal window:
git clonehttps://github.com/dvquy13/gcp_ml_pipeline.git
cd gcp_ml_pipeline- 👉 Select
Filethen open the filegcp_ml_pipeline/configs/.project_env:
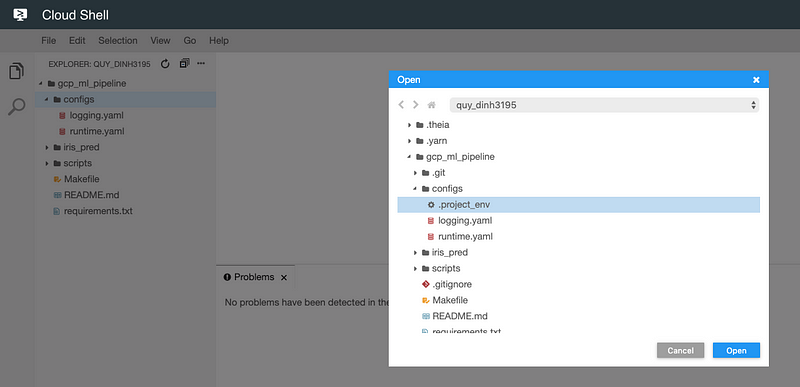
- 👉 Replace the values enclosed by <>. For the
GCP_PROJECT, you need to provide theidof your GCP project. For the remaining, feel free to choose some random names for the global variables that identify your resources. The final output looks like this:
GCP_PROJECT='zinc-primer-230105'
GCS_BUCKET=dvquys-tut-gcp-ml-pipeline
DATA_LOCATION=us-east1
BQ_DATASET=tut_iris
BQ_ORG_TABLE=F_ORIGINAL
CLUSTER_NAME=iris-pred- 👉 Grant
executepermission to the folder scripts by running the command:chmod +x -R ./scripts. Then, run./scripts/00_import_data_to_bigquery.sh. Link to the script.
Step 3: Create Dataproc cluster and submit jobs
We use Makefile to orchestrate our actions. You can find it here.
️Now, run the following commands in sequence:
make create-dataproc-cluster: This command creates a Dataproc cluster. Thesingle-nodeflag indicates that this is a cluster containing only one machine.n1-standard-1is the cheapest machine we can rent. To install Python packages, we supply themetadataandinitialization-actionsparams.make build: Package your code, including your source code and other 3rd party libraries that you can not pre-install when creating the cluster (PyYAML for example). To submit a job to the cluster, we will send these codes to those machines via thegcloud dataproc jobs submit pysparkcommand.make submit-job ENV=dev MODULE=data_import TASK=query_train_pred: Submit job cloning input data for training and predicting. Thesubmit-jobmakecommand allows you to use this interface to run on both local and development environments.make submit-job ENV=dev MODULE=feature_engineer TASK=normalize: Prepare features. In this illustrative example, we choose to include only normalization in the pipeline. After learning the normalization parameters from the train data set, we save those configurations for later usage.make submit-job ENV=dev MODULE=model TASK=fit: Train model. Here we build a pipeline consisting of 2 steps, Normalization and Logistic Regression. After that, we persist the fit pipeline.make submit-job ENV=dev MODULE=predict TASK=batch_predict: Batch predict. This job demonstrates the process when you use your learned model to make predictions.make submit-job ENV=dev MODULE=predict TASK=store_predictions: Store predictions. The reason we do not combine this with the above step is two-fold. First, writing to a database often takes time and requires several retries. Second, we write to a document database like Cloud Firestore because when other team uses, they typically retrieve one document per query. However, there are times when we want to inspect the whole batch of predictions (e.g. debugging, count number of documents scored more than 0.9). For this query pattern, we will better off using the persisted outputs from the previous step, stored as parquet files in Cloud Storage.make delete-dataproc-cluster: Delete Dataproc cluster. After the process finishes, delete the cluster so no further cost incurs.

Succeeded Dataproc jobs
You can see that your predictions are stored at Cloud Firestore by accessing its web console.
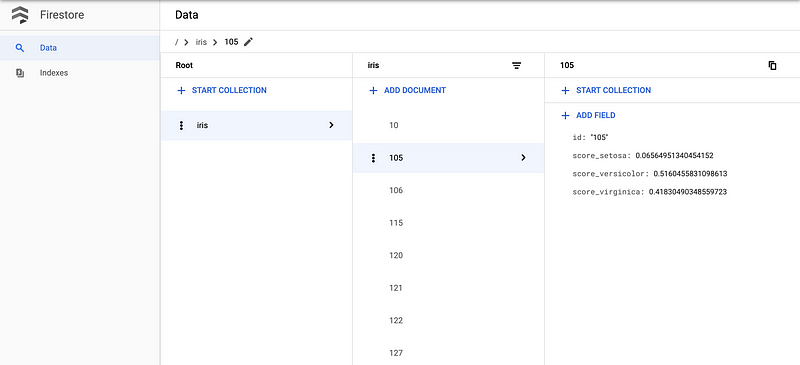
Firestore populated with predictions
Along the way, you will see that the output data of each step is persisted in Cloud Storage. I use parquet rather than CSV as the serialization format because it can embed schema information (therefore you do not have to specify column types when reading) and reduce storage size. For more detail, please refer to this benchmark.
Clean up
- 👉 Finally, when you’re done exploring the results, you can delete all resources by running these commands:
./scripts/01_erase_resources.sh
./scripts/02_disable_resources.sh
./scripts/03_delete_project.shExplain codebase
scripts/: This directory contains some initial scripts, which are the steps to help you set things up. In practice, I also favor using script rather than user interfaces such as web console because it is self-documented and easy for others to follow the exact steps.
configs/: Store all the arguments that need to be set initially. .project_env is a file to store the global variables used to work with GCP. We also have the runtime.yaml, where we use Anchor, Alias and Extension in YAML to define runtime parameters for multiple environments. Both of these files serve as a centralized config store so that we can easily look up and make changes, instead of finding the configs scattered elsewhere in the code.
Makefile: Originally Makefile is used to orchestrate the build process in C programming language. But it has done so well out of being just a shortcut so people start using it to facilitate ML model development. I have seen many tutorials using this tool, including the one that inspires me to design my Pyspark codebase.In this small project, we also use Makefile to save us a lot of time. As you can see above in Step 3, I put there our frequently used commands so that I can easily type make <something> to run a particular step.
iris_pred/: Source code.
main.py: is the interface to all tasks. This file parses the arguments to load config and get the job name, then call analyze function in entry_point.py from the appropriate module.
jobs/: contain tasks as modules. Inside jobs, we have one module corresponding to a step in our pipeline. All these modules expose an entry_point.py file where we unify the API to easily and consistently communicate with main.py.
Code: train.py
iris_pred/jobs/model/train.py
import logging
logger = logging.getLogger(__name__)
import subprocess
from shared.io_handler import IOHandler
from jobs.feature_engineer.normalize import FeatureNormalizer
from sklearn.externals import joblib
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
class Trainer:
def __init__(self, params, load: bool):
self.params = params
self.io_handler = IOHandler(params)
self.interim_output_path, self.final_output_path = \
self._get_fpath()
self.normalizer = None
self.learner = None
self.pipeline = None
def _get_fpath(self):
interim_output_path = \
f'../{self.params.io.pipeline}/pipeline.joblib'
final_output_path = \
f'{self.io_handler.fpath_dict.pipeline}/pipeline.joblib'
return interim_output_path, final_output_path
def _load_train_data(self):
X_train = self.io_handler.load('X_train')
y_train = self.io_handler.load('y_train')['species']
return X_train, y_train
def _load_transformer(self):
normalizer_wrapper = FeatureNormalizer(self.params, load=True)
self.normalizer = normalizer_wrapper.normalizer
def _initiate_learner(self):
self.learner = LogisticRegression()
def _make_pipeline(self):
self.pipeline = make_pipeline(
self.normalizer,
self.learner)
def _fit(self, X_train, y_train):
self.pipeline.fit(X_train, y_train)
def _persist_pipeline(self):
# Temporarily save model to disk
joblib.dump(self.pipeline, self.interim_output_path)
# Copy model to GCS
if self.params.env_name != 'local':
logger.info(f"Persisting {self.final_output_path}...")
subprocess.check_output([
'gsutil', '-m', 'cp', '-r',
self.interim_output_path,
self.final_output_path])
def run(self):
X_train, y_train = self._load_train_data()
self._load_transformer()
self._initiate_learner()
self._make_pipeline()
self._fit(X_train, y_train)
self._persist_pipeline()As you can see in the snippet above, the class Trainer expose a function run. Each step in the process corresponds to a private function declared in the same class.
shared/: functions and classes to be reused across modules
In io_handler.py, the class IOHandler applies the principle Composition Over Inheritance to ease the process of loading outputs from the previous step.
Further discussion
To completely build and operate a pipeline, there is still more to be considered.
Apache Spark for bigger data
In this tutorial, we rent one small machine from Dataproc and use pandas as our preprocessing engine, which perfectly handles the case of data fit into the memory of that machine. However, often data input in real-world situations will be much bigger, therefore require us to use a distributed computing framework for scalability. In that case, you can just switch to using Apache Spark. From version 1.3, Spark introduces its DataFrame API, which greatly bears resemblance to Pandas counterpart. After porting your code from Pandas to Spark, to be able to run jobs across multiple machines, you just need to create a bigger cluster with a master and multiple workers.
Apache Airflow for orchestration
Most of the batch job is not ad hoc. If it is, we should not even think about putting effort to standardize the process in the first place. Apache Airflow can play the role of both a scheduler and a monitor. It keeps metadata of each run and can send you alerts when things fail.
An alternative is Dataproc Workflows. This is a native solution offered by GCP, but I haven’t tried it myself so I will just leave the documentation here.
Local development
Because rarely our codes work the first time we write them, it’s very important to be able to quickly test without having to go through all the boilerplate steps from setting up variables to requesting cloud resources. My suggestion is that we should set up our local environment asap. We can install Apache Spark 2.4.3+ to act as our runner engine, and MongoDB to be our alternative for Cloud Firestore. Here in the code repo, you can still refer to some line containing what I call the “environment branching logic”, which enables you to switch between running the same code on both local and cloud environments.
Unit testing
Many people have already talked about unit testing, so I won’t go too detailed here. I also don’t do unit testing in this tutorial for the sake of simplicity. However, I strongly encourage you to add testing yourself. Whatever it takes, unit testing forces us to modularize our code and add a layer of alerting. This is very important because things in data science often break in silence.
Summary
Here is a summary of what you have learned in this tutorial:
- How to utilize different Google Cloud Platform components to build a batch job pipeline (whether it involves ML or not).
- A product named Google Cloud Dataproc, where you can both submit a light-weight job via single-node mode and easily scale to a cluster of computers.
- One approach to structurize ML pipeline codebase: Link to the repo.
- Some convenient components in model development, e.g. Makefile, runtime config, parquet persistence. This mostly helps people with little or no software engineering background.
Again, one of my main goals in writing this article is to receive feedback from the community, so I can do my job better. Please feel free me leave me comments, and I hope you guys enjoy this tutorial.
References
Ricky Kim. (Dec 2018). PySpark Sentiment Analysis on Google Dataproc. towardsdatascience.com. https://towardsdatascience.com/step-by-step-tutorial-pyspark-sentiment-analysis-on-google-dataproc-fef9bef46468.
Evan Kampf. (Jan 2017). Best Practices Writing Production-Grade PySpark Jobs. developerzen.com. https://developerzen.com/best-practices-writing-production-grade-pyspark-jobs-cb688ac4d20f.
King Chung Huang. (Oct 2017). Don’t Repeat Yourself with Anchors, Aliases and Extensions in Docker Compose Files. medium.com. https://medium.com/@kinghuang/docker-compose-anchors-aliases-extensions-a1e4105d70bd.
Credits
Kudos to Bido for reviewing my work; to anh Khanh, anh Linh, anh Tuan for providing me feedback.
If you find this article helpful, please cite this writeup as:
Quy, Dinh. (Feb 2020). From Model to Production: Deploying Your Machine Learning Solution on Google Cloud. dvquys.com. https://dvquys.com/posts/deploy-ml-gcp/.